
|
Data Fetching |

1, NYC DOT Real-time Camera
NYC DOT provides web access to all of its real-time street cameras from dotsignals.org . In order to access these videos legally, we signed an agreement contract with NYC DOT and used a web page crawler provided by Zheng Shou from Columbia University. By accessing this web crawler, http://dotsignals.org/google_popup.php?cid=931 , we are able to analyze real-time NYC street video as well as recording data for research use.
2, Camera Setup
NYC DOT cameras are set up in many different streets and in many different angles. Since the main objective we trying to achieve here is to find out available street parking spots in the city, many cameras do not possess the angles we would consider as “good angles”. Also, the frame rate and resolution are very low for NYC DOT cameras. In order to start with something that’s easy to analyze, we set up two cameras at different location to get high resolution, high frame rate video with good angles on streets. 50 GB of video is recorded.
NYC DOT provides web access to all of its real-time street cameras from dotsignals.org . In order to access these videos legally, we signed an agreement contract with NYC DOT and used a web page crawler provided by Zheng Shou from Columbia University. By accessing this web crawler, http://dotsignals.org/google_popup.php?cid=931 , we are able to analyze real-time NYC street video as well as recording data for research use.
2, Camera Setup
NYC DOT cameras are set up in many different streets and in many different angles. Since the main objective we trying to achieve here is to find out available street parking spots in the city, many cameras do not possess the angles we would consider as “good angles”. Also, the frame rate and resolution are very low for NYC DOT cameras. In order to start with something that’s easy to analyze, we set up two cameras at different location to get high resolution, high frame rate video with good angles on streets. 50 GB of video is recorded.
Video Analysis










|
1, Parking Region Recognition
During our development process, many obstacles came up. The trees in the camera changes very frequent due to wind. This generate a lot of noise to us and can be omitted by performing second order frame difference accumulation. The change of sunshine also generates a lot of noise for the whole frame because the color for a whole frame changes rapidly. This can be omitted by discarding such frames if too much difference is generated among consecutive frames.
2, Parking Spot Identification
--------------------------Noise_free_BG_subtraction_50s_window.py--------------------------------------- gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY) gray = np.float64(gray) if count >300: gray_sum = gray_sum+gray tmp = old_frame - frame tmp_gray = old_gray - gray tmp_gray_sum = tmp_gray_sum+tmp_gray accumulated = accumulated + tmp_gray_sum_old - tmp_gray_sum accumulated = np.uint8(np.clip(accumulated,0,255)) tmp_gray_sum = np.uint8(np.clip(tmp_gray_sum,0,255)) tmp_gray_sum_old = tmp_gray_sum cv2.imshow('accumulated',accumulated) cv2.imshow('tmp_gray_sum',tmp_gray_sum) old_frame = frame old_gray = gray count+=1 count_2+=1 -------------------------------------------------------------------------------------------------------------- This algorithm also works very well in test cases. The difference between two 50 seconds mean frames successfully identifies the absence of a car and the leaving of another car. By comparing the color of the region which has pixels changes at a size of a car and the color of active driving region color, we are able to tell if a car is leaving or moving away. However, a difficulty is impeding the algorithm. For example, such case would be really hard to handle: if in 1st 50s window, car stayed for 50s; in 2nd 50s window, car stayed for 40s and left at 26th second; in 3rd 50s window, car was gone. In this case, the difference between 1st and 2nd window is barely noticeable. If we amplify the difference between 1st and 2nd window, a lot of noise would be generated.
------------------------------Motion_detection_50s_window.py-------------------------------------------- gray_sum = gray_sum+gray tmp = old_frame - frame tmp_gray = old_gray - gray tmp_gray_sum = tmp_gray_sum+tmp_gray tmp_gray_sum = np.uint8(np.clip(tmp_gray_sum,0,255)) if count%1500 == 0 and flag == 0: flag = 1 cv2.imshow('current',tmp_gray_sum) ggggg = np.float64(tmp_gray_sum) tmp_min.append(ggggg) tmp_gray_sum = 0 if len(tmp_min) >=2: old = np.uint8(np.clip(tmp_min[len(tmp_min)-2],0,255)) cv2.imshow('old',old) pic = tmp_min[len(tmp_min)-1]-tmp_min[len(tmp_min)-2] pic = np.uint8(np.clip(pic,0,255)) cv2.imshow('diff',pic) k = input() print 'one pic added' if count%1500 != 0 and flag == 1: flag = 0 -------------------------------------------------------------------------------------------------------------- This makes the spot more noticeable than previous algorithm. However, this method works really bad when there are many available parking spaces. If a driver tries to park at a place where no car is in front of him or behind him, he tends to use many space to back into the spot. This would generated unwanted movement and cause failure toward this algorithm(Identifies it as more than one car has parked in.
The advantages to be gained with an edge detection are clear. This transforms allows for the smoothing of background to determine explicit edges along an otherwise smoothed out background. Very good for detecting lone objects amongst others. When applied to a street for the purpose of identifying parked cars, it becomes a bit more difficult to discern obvious edges.
However, the issue here was that the Haar Cascades were predominantly for the explicit backs of cars, or fronts of cars. It had an extremely high error rate in detecting cars from a side on, or a top down viewpoint(at least, for the model we had used)
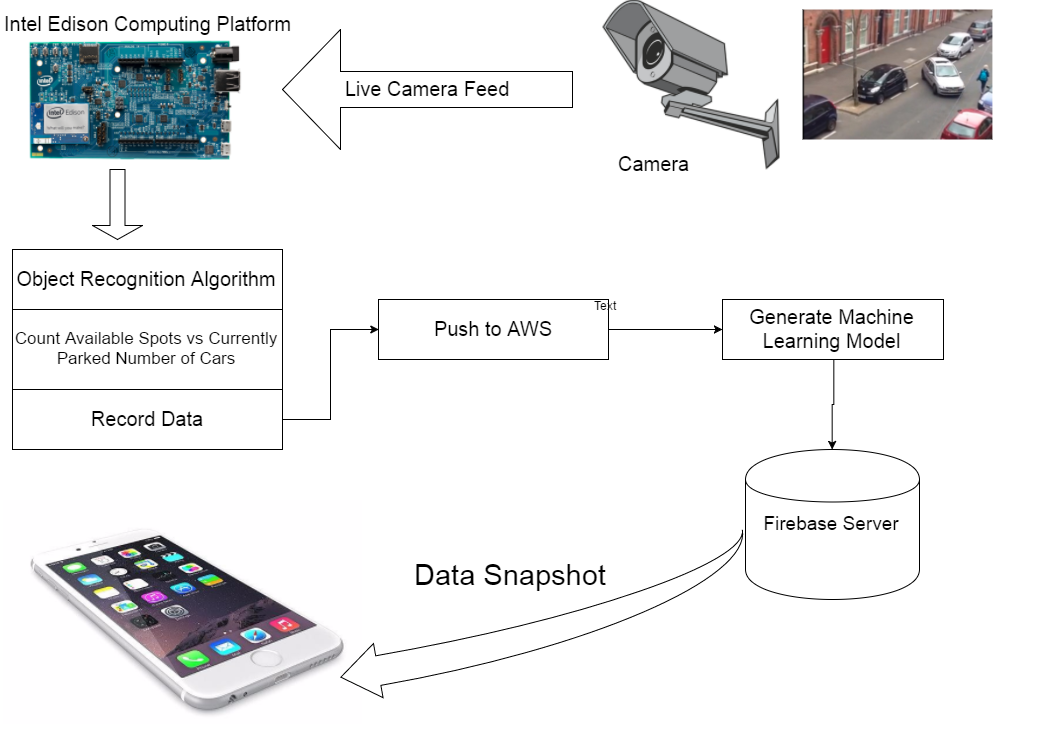
Due to hardware limit, although we invested almost two weeks in trying to implement this method, we were still not able to use this algorithm. It requires a desktop with good GPU card, running Ubuntu system with a lot of libraries from NVidia. Lack of hardware support disables us from using this algorithm. 3, Intel Edison
|
Machine learning Model
As a proof of concept, we implemented a machine learning model. Our current ML model is based off a collected data set about parking garages. Due to the challenges we faced in using Computer Vision to detect street parking of cars, collection of a robust data set sufficient for creating a machine learning model was inadequate.
Regardless, data cleaning was the beginning. The raw data consisted of a streamtime, and then information regarding the capacity of the parking lot. The raw number of cars that were currently parked was updated every 30 minutes. This data was taken over a single weekend, and while the resulting model is flawed, it does offer some particular insights about driver and parking behavior for certain times of day. For example, it pretty clearly demonstrates that at various times of day, the lots were almost guaranteed to be completely full. For others, that were primarily located near train stations, they were full throughout the day. For one of the lots, it was completely occupied exclusively at nighttime, and was generally open during the day. From the behavior of these garages it was possible to attempt to segment what type of behavior a street exhibited, and then determine the closest parallel. For the purposes of this application, we created a classifier machine learning model, which let us determine if a significant portion of parking spots were still available. Previous research conducted by INRIX has suggested that greater than 10% of overall parking spots still being available pretty much guarantees an available parking spot for an individual user (with other variables not yet considered).
This was the pushed onto Kinesis, where the code could be available for interfacing with our iOS app. We made the decision to not directly use this machine learning model, as given the quantity of parking spots we tracked for our various locations was significantly smaller than any of the parking garages, the model was a poor predictor for availability of parking.
Regardless, data cleaning was the beginning. The raw data consisted of a streamtime, and then information regarding the capacity of the parking lot. The raw number of cars that were currently parked was updated every 30 minutes. This data was taken over a single weekend, and while the resulting model is flawed, it does offer some particular insights about driver and parking behavior for certain times of day. For example, it pretty clearly demonstrates that at various times of day, the lots were almost guaranteed to be completely full. For others, that were primarily located near train stations, they were full throughout the day. For one of the lots, it was completely occupied exclusively at nighttime, and was generally open during the day. From the behavior of these garages it was possible to attempt to segment what type of behavior a street exhibited, and then determine the closest parallel. For the purposes of this application, we created a classifier machine learning model, which let us determine if a significant portion of parking spots were still available. Previous research conducted by INRIX has suggested that greater than 10% of overall parking spots still being available pretty much guarantees an available parking spot for an individual user (with other variables not yet considered).
This was the pushed onto Kinesis, where the code could be available for interfacing with our iOS app. We made the decision to not directly use this machine learning model, as given the quantity of parking spots we tracked for our various locations was significantly smaller than any of the parking garages, the model was a poor predictor for availability of parking.
Firebase Server Setup

The objective of using Firebase as our data host is because it’s very user friendly to frontend developers and backend developers. Although Amazon does provide better service and much more functions than Firebase, it is also has higher accessing complexity. Since we are starting with small data set, FIrebase satisfies our requirements while providing much more convenient than Amazon AWS.
Also, Firebase has more user-friendly testing system. It’s easier to manually manipulate Firebase database through web console than manipulating AWS database through web console.
Due to the fact that we have not yet established a mutual parking information abstraction system, we only wrote a skeleton and uploaded some test cases to Firebase Database.
Also, Firebase has more user-friendly testing system. It’s easier to manually manipulate Firebase database through web console than manipulating AWS database through web console.
Due to the fact that we have not yet established a mutual parking information abstraction system, we only wrote a skeleton and uploaded some test cases to Firebase Database.
User Interface/iOS app
The iOS application is written with the Facebook application framework React Native. The framework enables developers to develop applications on native platforms using a consistent developer experience based on JavaScript and ReactJS.
The application supports Facebook login currently and fetch user avatar and name directly from Facebook. It talks to the project database on Firebase directly, parse the response Json data and indicates the availability of the two test spots with pin color and pin annotations.
Useage is pretty much straight forward, the map view will go straight to user’s current position to simulate the scene of finding a parking nearby, press the Refresh button on the upper right corner to fetch data, if there is available parking spot, the pin color would be turned to green with an ‘Available’ annotation.
Useage is also pretty much straight forward, the map view will be directed straightly to user’s current position to simulate the scene of finding a parking nearby, press the Refresh button on the upper right corner to fetch data, if there is available parking spot, the pin color would be turned to green with an ‘Available’ annotation. There will be a notification once there is a data successfully fetched from Firebase.
Because server overwrites previous data set everything it operates a push request to Firebase, the data fetched by the application will always be real time, on an 10 min basis.
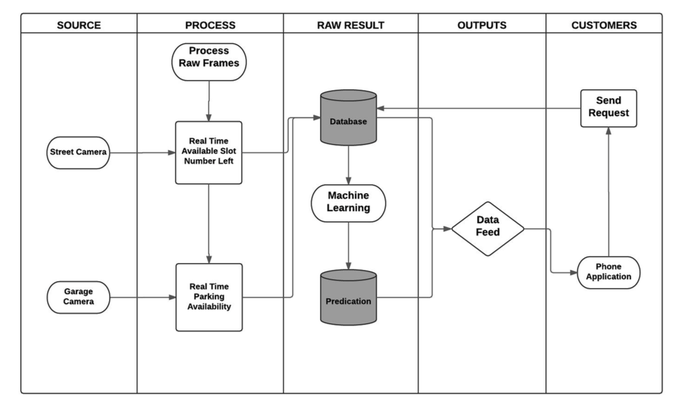
Functional Flowchart